足球是世界上最火爆的运动,今天我们将使用英超比赛的历史结果统计信息来预测未来英超比赛的结果。英超一年一个赛季,每年20个球队参赛,共计380场比赛。
数据处理
我们下载英超在2005年-2018年的比赛数据。用 pandas 把历年的 csv 数据都导入进来。
import pandas as pd
# 读取原始数据
loc = "./football/"
raw_data_1 = pd.read_csv(loc + '2005-06.csv')
...此处省略其他年份的比赛数据
raw_data_13 = pd.read_csv(loc + '2017-18.csv')
我们看看05-06年的前五条。
raw_data_1.head()

我们看到包括数据包括 Date(比赛的时间),Hometeam(主场队伍名),Awayteam(客场队伍名),FTHG(主场球队全场进球数),HTHG(主场球队半场进球数),FTR(全场比赛结果)等等。更多数据的介绍可以参考这里。
我们挑选 Hometeam,Awayteam,FTHG,FTAG,FTR 这五列数据,作为我们的原始的特征数据,后面基于这些原始特征,我们再构造一些新的特征。
columns_req = ['HomeTeam','AwayTeam','FTHG','FTAG','FTR']
playing_statistics_1 = raw_data_1[columns_req]
...
playing_statistics_13 = raw_data_13[columns_req]
因为这个比赛是一年一个赛季,是有先后顺序的,那我们就可以统计到截止到本场比赛之前,整个赛季内,主客场队伍的净胜球的数量。
# 计算每个队周累计净胜球数量
def get_goals_diff(playing_stat):
# 创建一个字典,每个 team 的 name 作为 key
teams = {}
for i in playing_stat.groupby('HomeTeam').mean().T.columns:
teams[i] = []
# 对于每一场比赛
for i in range(len(playing_stat)):
# 全场比赛,主场队伍的进球数
HTGS = playing_stat.iloc[i]['FTHG']
# 全场比赛,客场队伍的进球数
ATGS = playing_stat.iloc[i]['FTAG']
# 把主场队伍的净胜球数添加到 team 这个 字典中对应的主场队伍下
teams[playing_stat.iloc[i].HomeTeam].append(HTGS-ATGS)
# 把客场队伍的净胜球数添加到 team 这个 字典中对应的客场队伍下
teams[playing_stat.iloc[i].AwayTeam].append(ATGS-HTGS)
# 创建一个 GoalsScored 的 dataframe
# 行是 team 列是 matchweek
GoalsDifference = pd.DataFrame(data=teams, index = [i for i in range(1,39)]).T
GoalsDifference[0] = 0
# 累加每个队的周比赛的净胜球数
for i in range(2,39):
GoalsDifference[i] = GoalsDifference[i] + GoalsDifference[i-1]
return GoalsDifference
def get_gss(playing_stat):
# 得到净胜球数统计
GD = get_goals_diff(playing_stat)
j = 0
HTGD = []
ATGD = []
# 全年一共380场比赛
for i in range(380):
ht = playing_stat.iloc[i].HomeTeam
at = playing_stat.iloc[i].AwayTeam
HTGD.append(GD.loc[ht][j])
ATGD.append(GD.loc[at][j])
if ((i + 1)% 10) == 0:
j = j + 1
# 把每个队的 HTGS ATGS 信息补充到 dataframe 中
playing_stat.loc[:,'HTGD'] = HTGD
playing_stat.loc[:,'ATGD'] = ATGD
return playing_stat
playing_statistics_1 = get_gss(playing_statistics_1)
...
playing_statistics_13 = get_gss(playing_statistics_13)
例如,我们看376行, 截止到这一场比赛之前,本赛季,主场曼联队的净胜球数是34, 客场查尔顿队的净胜球数是-10。
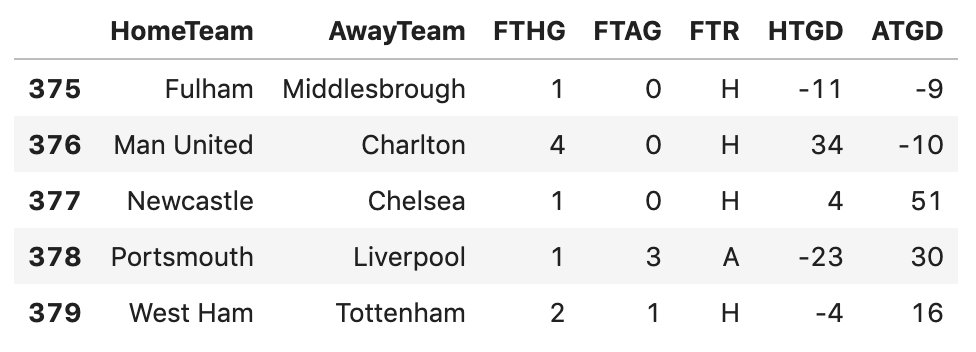
我们还可以统计整个赛季主客场队伍截止到当前比赛周的累计得分。一场比赛胜利积3分, 平局积1分,输了积0分。我们根据本赛季本周之前的比赛结果来统计这个值。
# 把比赛结果转换为得分,赢得三分,平局得一分,输不得分
def get_points(result):
if result == 'W':
return 3
elif result == 'D':
return 1
else:
return 0
def get_cuml_points(matchres):
matchres_points = matchres.applymap(get_points)
for i in range(2,39):
matchres_points[i] = matchres_points[i] + matchres_points[i-1]
matchres_points.insert(column =0, loc = 0, value = [0*i for i in range(20)])
return matchres_points
def get_matchres(playing_stat):
# 创建一个字典,每个 team 的 name 作为 key
teams = {}
for i in playing_stat.groupby('HomeTeam').mean().T.columns:
teams[i] = []
# 把比赛结果分别记录在主场队伍和客场队伍中
# H:代表 主场 赢 A:代表 客场 赢 D:代表 平局
for i in range(len(playing_stat)):
if playing_stat.iloc[i].FTR == 'H':
# 主场 赢,则主场记为赢,客场记为输
teams[playing_stat.iloc[i].HomeTeam].append('W')
teams[playing_stat.iloc[i].AwayTeam].append('L')
elif playing_stat.iloc[i].FTR == 'A':
# 客场 赢,则主场记为输,客场记为赢
teams[playing_stat.iloc[i].AwayTeam].append('W')
teams[playing_stat.iloc[i].HomeTeam].append('L')
else:
# 平局
teams[playing_stat.iloc[i].AwayTeam].append('D')
teams[playing_stat.iloc[i].HomeTeam].append('D')
return pd.DataFrame(data=teams, index = [i for i in range(1,39)]).T
def get_agg_points(playing_stat):
matchres = get_matchres(playing_stat)
cum_pts = get_cuml_points(matchres)
HTP = []
ATP = []
j = 0
for i in range(380):
ht = playing_stat.iloc[i].HomeTeam
at = playing_stat.iloc[i].AwayTeam
HTP.append(cum_pts.loc[ht][j])
ATP.append(cum_pts.loc[at][j])
if ((i + 1)% 10) == 0:
j = j + 1
# 主场累计得分
playing_stat.loc[:,'HTP'] = HTP
# 客场累计得分
playing_stat.loc[:,'ATP'] = ATP
return playing_stat
playing_statistics_1 = get_agg_points(playing_statistics_1)
...
playing_statistics_13 = get_agg_points(playing_statistics_13)
我们处理得到HTP(本赛季主场球队截止到本周的累计得分), ATP (本赛季客场球队截止到本周的累计得分)。
我们再看376行,截止到这一场比赛,本赛季,曼联队一共积了80分, 查尔顿队积了47分。
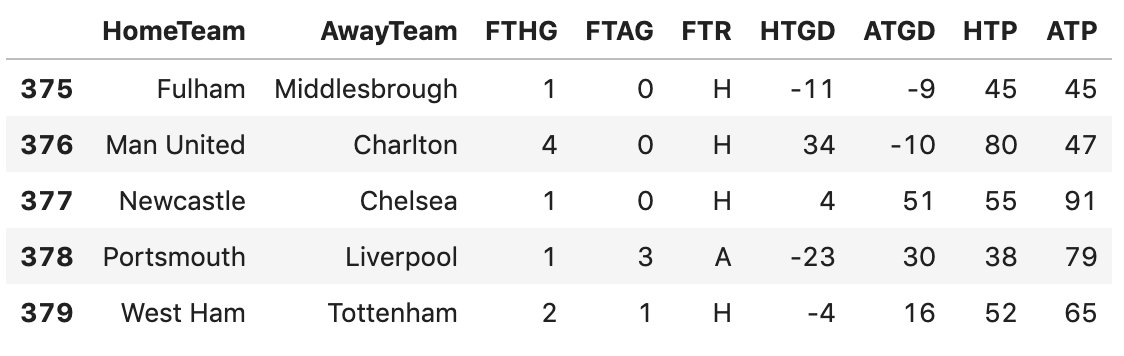
前面我们构造的特征反映了一只队伍本赛季的历史总表现,我们看看队伍在最近三场比赛的表现。我们用 HM1 代表主场球队上一次比赛的输赢,AM1 代表客场球队上一次比赛是输赢。同理,HM2 AM2 就是上上次比赛的输赢, HM3 AM3 就是上上上次比赛的输赢。
# 上 n 次的比赛结果
# 例如:
# HM1 代表上次主场球队的比赛结果
# HM2 代表上上次主场球队的比赛结果
# AM1 代表上次客场球队的比赛结果
# AM2 代表上上次客场球队的比赛结果
def get_form(playing_stat,num):
form = get_matchres(playing_stat)
form_final = form.copy()
for i in range(num,39):
form_final[i] = ''
j = 0
while j < num:
form_final[i] += form[i-j]
j += 1
return form_final
def add_form(playing_stat,num):
form = get_form(playing_stat,num)
# M 代表 unknown, 因为没有那么多历史
h = ['M' for i in range(num * 10)]
a = ['M' for i in range(num * 10)]
j = num
for i in range((num*10),380):
ht = playing_stat.iloc[i].HomeTeam
at = playing_stat.iloc[i].AwayTeam
past = form.loc[ht][j]
h.append(past[num-1])
past = form.loc[at][j]
a.append(past[num-1])
if ((i + 1)% 10) == 0:
j = j + 1
playing_stat['HM' + str(num)] = h
playing_stat['AM' + str(num)] = a
return playing_stat
def add_form_df(playing_statistics):
playing_statistics = add_form(playing_statistics,1)
playing_statistics = add_form(playing_statistics,2)
playing_statistics = add_form(playing_statistics,3)
return playing_statistics
playing_statistics_1 = add_form_df(playing_statistics_1)
...
playing_statistics_13 = add_form_df(playing_statistics_13)
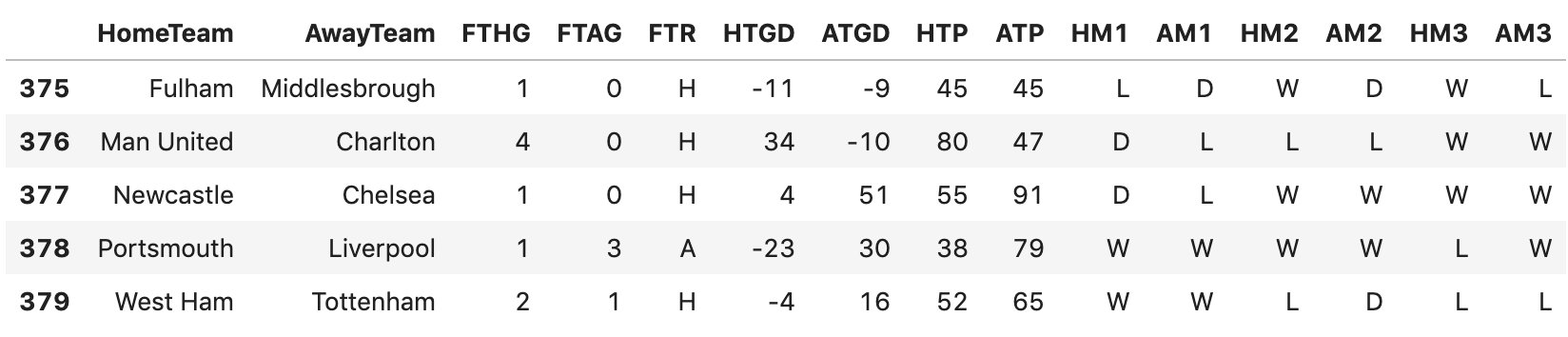
然后我们把比赛周的信息也放在里面,也就是这一场比赛发生在第几个比赛周。
# 加入比赛周特征(第几个比赛周)
def get_mw(playing_stat):
j = 1
MatchWeek = []
for i in range(380):
MatchWeek.append(j)
if ((i + 1)% 10) == 0:
j = j + 1
playing_stat['MW'] = MatchWeek
return playing_stat
playing_statistics_1 = get_mw(playing_statistics_1)
...
playing_statistics_13 = get_mw(playing_statistics_13)
接下来,我们把这几年的比赛的信息都合并到一个表里面。然后我们把我们刚才计算得到的这些得分数据,净胜球数据除以周数,就得到了周平均后的值。
playing_stat = pd.concat([playing_statistics_1,
...
playing_statistics_13], ignore_index=True)
# HTGD, ATGD ,HTP, ATP的值 除以 week 数,得到平均分
cols = ['HTGD','ATGD','HTP','ATP']
playing_stat.MW = playing_stat.MW.astype(float)
for col in cols:
playing_stat[col] = playing_stat[col] / playing_stat.MW

前面我们根据初始的特征构造出了很多的特征。这其中有一部分是中间的特征,我们把这些中间特征抛弃掉抛弃掉。因为前三周的比赛,每个队的历史胜负信息不足,我们弃掉前三周的数据。
# 抛弃前三周的比赛,抛弃队名和比赛周信息
playing_stat = playing_stat[playing_stat.MW > 3]
playing_stat.drop(['HomeTeam', 'AwayTeam', 'FTHG', 'FTAG', 'MW'],1, inplace=True)
我们的标签是FTR(全场比赛结果),我们看一下是主场胜利的多呢?还是客场胜利的多?
# 比赛总数
n_matches = playing_stat.shape[0]
# 主场获胜的数目
n_homewins = len(playing_stat[playing_stat.FTR == 'H'])
# 主场获胜的比例
win_rate = (float(n_homewins) / (n_matches)) * 100
# 输出结果
print("比赛总数: {}".format(n_matches))
print("主场胜利数: {}".format(n_homewins))
print("主场胜率: {:.2f}%".format(win_rate))
比赛总数: 4940
主场胜利数: 2300
主场胜率: 46.56%
通过统计结果看到,主场获胜的比例接近50%,所以对于这个三分类的问题,标签比例是不均衡的。
我们把它简化为2分类问题,也就是主场球队会不会胜利,这也是一种解决标签比例不均衡的问题的方法。
# 定义 target ,也就是否 主场赢
def only_hw(string):
if string == 'H':
return 'H'
else:
return 'NH'
playing_stat['FTR'] = playing_stat.FTR.apply(only_hw)
数据切分
接下来我们来切分数据,使用 sklearn 来进行数据切分真的超级简单,一行就搞定了。而且它会自动的进行一个 shuffle, 也就是混洗数据。 这里有一个设置,stratify就是让切分出来的 test set 能保持 y 的比例。
# 数据分为特征和标签
X_all = playing_stat.drop(['FTR'],1)
y_all = playing_stat['FTR']
from sklearn.model_selection import train_test_split
# 把数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_all, y_all, test_size = 50,random_state = 2,stratify = y_all)
模型训练与评估
下面我们分别使用线性回归,支持向量机和 xgboost这三种不同的模型,来看看他们的表现。
我们先定义一些辅助函数,记录模型的训练时长和评估时长,计算模型的准确率和 f1 分数。
from time import time
from sklearn.metrics import f1_score
def train_classifier(clf, X_train, y_train):
''' 训练模型 '''
# 记录训练时长
start = time()
clf.fit(X_train, y_train)
end = time()
print("训练时间 {:.4f} 秒".format(end - start))
def predict_labels(clf, features, target):
''' 使用模型进行预测 '''
# 记录预测时长
start = time()
y_pred = clf.predict(features)
end = time()
print("预测时间 in {:.4f} 秒".format(end - start))
return f1_score(target, y_pred, pos_label='H'), sum(target == y_pred) / float(len(y_pred))
def train_predict(clf, X_train, y_train, X_test, y_test):
''' 训练并评估模型 '''
# Indicate the classifier and the training set size
print("训练 {} 模型,样本数量{}".format(clf.__class__.__name__, len(X_train)))
# 训练模型
train_classifier(clf, X_train, y_train)
# 在测试集上评估模型
f1, acc = predict_labels(clf, X_train, y_train)
print("训练集上的 F1 分数和准确率为: {:.4f} ,{:.4f}.".format(f1 , acc))
f1, acc = predict_labels(clf, X_test, y_test)
print("测试集上的 F1 分数和准确率为: {:.4f} ,{:.4f}.".format(f1 , acc))
然后分别初始化,训练和评估这三个模型。
import xgboost as xgb
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
# 分别建立三个模型
clf_A = LogisticRegression(random_state = 42)
clf_B = SVC(random_state = 42, kernel='rbf',gamma='auto')
clf_C = xgb.XGBClassifier(seed = 42)
train_predict(clf_A, X_train, y_train, X_test, y_test)
print('')
train_predict(clf_B, X_train, y_train, X_test, y_test)
print('')
train_predict(clf_C, X_train, y_train, X_test, y_test)
print('')
从 f1 分数 和 准确率来看 xgboost 效果最好。 那我们选择它来作为我们最终的分类器。
训练 LogisticRegression 模型,样本数量 4500. . .
训练时间 0.0250 秒
预测时间 in 0.0032 秒
训练集上的 F1 分数和准确率为: 0.6197 , 0.6591.
预测时间 in 0.0013 秒
测试集上的 F1 分数和准确率为: 0.6190 , 0.6800.
训练 SVC 模型,样本数量 4500. . .
训练时间 1.5298 秒
预测时间 in 0.8834 秒
训练集上的 F1 分数和准确率为: 0.6031 , 0.6707.
预测时间 in 0.0107 秒
测试集上的 F1 分数和准确率为: 0.5641 , 0.6600.
训练 XGBClassifier 模型,样本数量 4500. . .
训练时间 0.3817 秒
预测时间 in 0.0233 秒
训练集上的 F1 分数和准确率为: 0.6415 , 0.6938.
预测时间 in 0.0014 秒
测试集上的 F1 分数和准确率为: 0.6829 , 0.7400.
然后我们可以把模型保存下来,以后用来做预测。
import joblib
#保存模型
joblib.dump(clf, 'xgboost_model.model')
#读取模型
xgb = joblib.load('xgboost_model.model')
然后我们尝试来进行一个预测。
sample1 = X_test.sample(n=1, random_state=1)
y_pred = xgb.predict(sample1)
我们看到育德结果是主场队伍会赢。
array(['H'], dtype=object)
部署
接下来我们就可以把模型部署起来,让其他的人也可以用啦。 momodel.cn 提供了很方便的模型部署功能。
我们把模型用代码包装起来,处理模型的输入输出,然后存为一个 handler.py 文件,
import pandas as pd
import joblib
def handle(conf):
# 把用户输入的 dict 转为 dataframe 格式, 并调整好特征的顺序
df = pd.DataFrame(conf, index=[0])
df=df[[ 'HTP', 'ATP', 'HM1_D', 'HM1_L', 'HM1_W', 'AM1_D',
'AM1_L', 'AM1_W', 'HM2_D', 'HM2_L', 'HM2_W', 'AM2_D', 'AM2_L', 'AM2_W',
'HM3_D', 'HM3_L', 'HM3_W', 'AM3_D', 'AM3_L', 'AM3_W','HTGD', 'ATGD',]]
# 载入模型
model = joblib.load('xgboost_model.model')
# 使用模型进行预测
result = model.predict(df)
# 返回预测的结果
return {'res': result.tolist()[0]}
然后在 app_spech.yml 中定义用户需要的输入,以及handler.py的输出。
input:
HTGD:
name: HTGD
value_type: float
description: 主场队伍本赛季本次比赛前的平均净胜球数
ATGD:
name: ATGD
value_type: float
description: 客场队伍本赛季本次比赛前的平均净胜球数
HTP:
name: HTP
value_type: float
description: 主场队伍本赛季本次比赛前的平均每周得分
ATP:
name: ATP
value_type: float
description: 客场队伍本赛季本次比赛前的平均每周得分
...此处省略了其他的参数的定义
具体的部署过程可以参考这里
总结
今天我们一起制作了一个预测英超足球比赛结果的应用,具体的代码在这里,大家可以 fork 这个项目,试一试使用其他比赛的数据,比如中超,来做出自己的应用哦。
当然,大家可以看到,做预测需要用户去计算一场比赛主客场队伍的相关信息,然后一个个输入,实在是太麻烦了,直接让用户选择比赛的队伍,然后程序去计算这些历史比赛信息不就可以了吗?我们下节课就讲讲怎么样自动的从网络上获取并处理历史比赛的结果,让用户只输入比赛双方的队名,就能使用这个应用,敬请期待哦。
我们处理得到 HTGS (本赛季主场球队截止到当前比赛周的进球总数),ATGS (本赛季客场球队截止到当前比赛周的进球总数),HTGC (本赛季主场球队截止到当前比赛周的丢球总数),ATGC (本赛季客场球队截止到当前比赛周的丢球总数)。 —————————————————————————————————————————— Mo (网址:http://momodel.cn ) 是一个支持 Python 的在线人工智能建模平台,能帮助你快速开发训练并部署 AI 应用。