引言
文本情感分析(也称为意见挖掘)是指用自然语言处理、文本挖掘以及计算机语言学等方法来识别和提取原素材中的主观信息。文本分析可分为词典分析和机器学习分析方法,对于词典分析,我们只不过调用了第三方提供的文本情感分析工具而已。但是问题来了,这些第三方工具是在别的数据集上面训练出来的,未必适合你的应用场景。例如有些情感分析工具更适合分析新闻,有的更善于处理微博数据……你拿过来,却是要对店铺评论信息做分析。这就如同你自己笔记本电脑里的网页浏览器,和图书馆电子阅览室的网页浏览器,可能类型、版本完全一样。但是你用起自己的浏览器,就是比公用电脑上的舒服、高效——因为你已经根据偏好,对自己浏览器上的“书签”、“密码存储”、“稍后阅读”都做了个性化设置。
使用机器学习的时候,首先我们需要对自然语言进行向量化处理,对自然语言文本做向量化(vectorization)的主要原因,是计算机看不懂自然语言。计算机,顾名思义,就是用来算数的。文本对于它(至少到今天)没有真正的意义。但是自然语言的处理,是一个重要问题,也需要自动化的支持。因此人就得想办法,让机器能尽量理解和表示人类的语言。假如这里有两句话:
I love the game. I hate the game.
那么我们就可以简单粗暴地抽取出以下特征(其实就是把所有的单词都罗列一遍):
- I
- love
- hate
- the
- game
对每一句话,都分别计算特征出现个数。于是上面两句话就转换为以下表格:

按照句子为单位,从左到右读数字,第一句表示为[1, 1, 0, 1, 1],第二句就成了[1, 0, 1, 1, 1]。这就叫向量化。这个例子里面,特征的数量叫做维度。于是向量化之后的这两句话,都有5个维度。你一定要记住,此时机器依然不能理解两句话的具体含义。但是它已经尽量在用一种有意义的方式来表达它们。注意这里我们使用的,叫做“一袋子词”(bag of words)模型。下面这张图(来自 ~https://goo.gl/2jJ9Kp~ ),形象化表示出这个模型的含义。
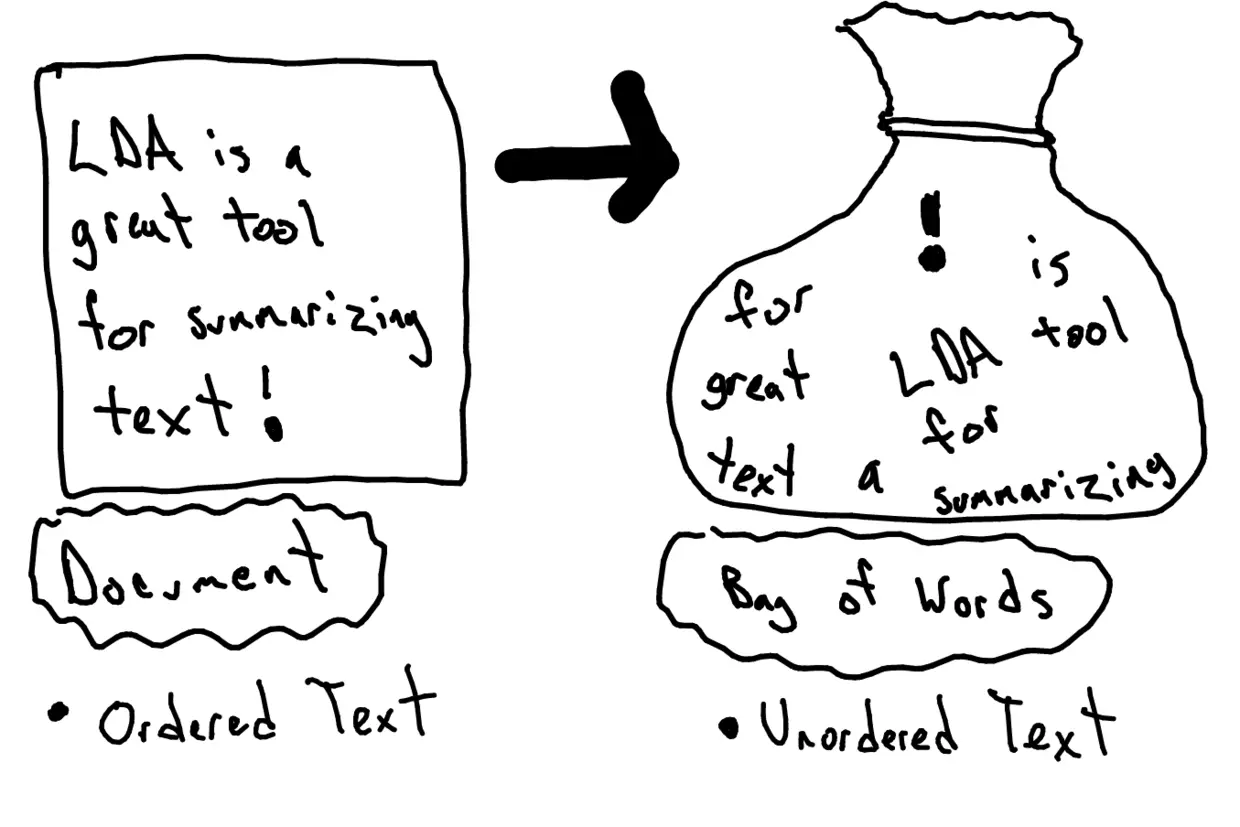
一袋子词模型不考虑词语的出现顺序,也不考虑词语和前后词语之间的连接。每个词都被当作一个独立的特征来看待。你可能会问:“这样不是很不精确吗?充分考虑顺序和上下文联系,不是更好吗?”没错,你对文本的顺序、结构考虑得越周全,模型可以获得的信息就越多。接下来介绍的Bert就是对NLP处理方式的优化。
1 BERT(Bidirectional Encoder Representations from Transformers)
2018年10月11日,Google AI Language 发布了论文BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上全面超越人类,并且还在11种不同NLP测试中创出最佳成绩,包括将GLUE基准推至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进率5.6%)等。可以预见的是,BERT将为NLP带来里程碑式的改变,也是NLP领域近期最重要的进展。
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不能获要预测的信息的。BERT 的创新点在于它将双向 Transformer 用于语言模型,之前的模型是从左向右输入一个文本序列,或者将 left-to-right 和 right-to-left 的训练结合起来。实验的结果表明,双向训练的语言模型对语境的理解会比单向的语言模型更深刻, 论文中介绍了一种新技术叫做 Masked LM(MLM),在这个技术出现之前是无法进行双向语言模型训练的。BERT 利用了 Transformer 的 encoder 部分。Transformer 是一种注意力机制,可以学习文本中单词之间的上下文关系的。 Transformer 的原型包括两个独立的机制,一个 encoder 负责接收文本作为输入,一个decoder 负责预测任务的结果。
BERT 的目标是生成语言模型,所以只需要 encoder 机制。Transformer 的encoder是一次性读取整个文本序列,而不是从左到右或从右到左地按顺序读取, 这个特征使得模型能够基于单词的两侧学习,相当于是一个双向的功能。
一句话概括,BERT的出现,彻底改变了预训练产生词向量和下游具体NLP任务的关系,提出龙骨级的训练词向量概念。传统意义上来讲,词向量模型是一个工具,可以把真实世界抽象存在的文字转换成可以进行数学公式操作的向量,而对这些向量的操作,才是NLP真正要做的任务。因而某种意义上,NLP任务分成两部分,预训练产生词向量,对词向量操作(下游具体NLP任务)。
从word2vec到ELMo到BERT,做的其实主要是把下游具体NLP任务的活逐渐移到预训练产生词向量上。BERT 提出一种新的预训练目标:遮蔽语言模型(masked language model,MLM),来克服上文提到的单向性局限。MLM 的灵感来自 Cloze 任务(Taylor, 1953)。MLM 随机遮蔽模型输入中的一些 token,目标在于仅基于遮蔽词的语境来预测其原始词汇 id。与从左到右的语言模型预训练不同,MLM 目标允许表征融合左右两侧的语境,从而预训练一个深度双向Transformer。除了遮蔽语言模型之外,本文作者还引入了一个“下一句预测”(next sentence prediction)任务,可以和MLM共同预训练文本对的表示。
1.1 Masked LM (MLM)
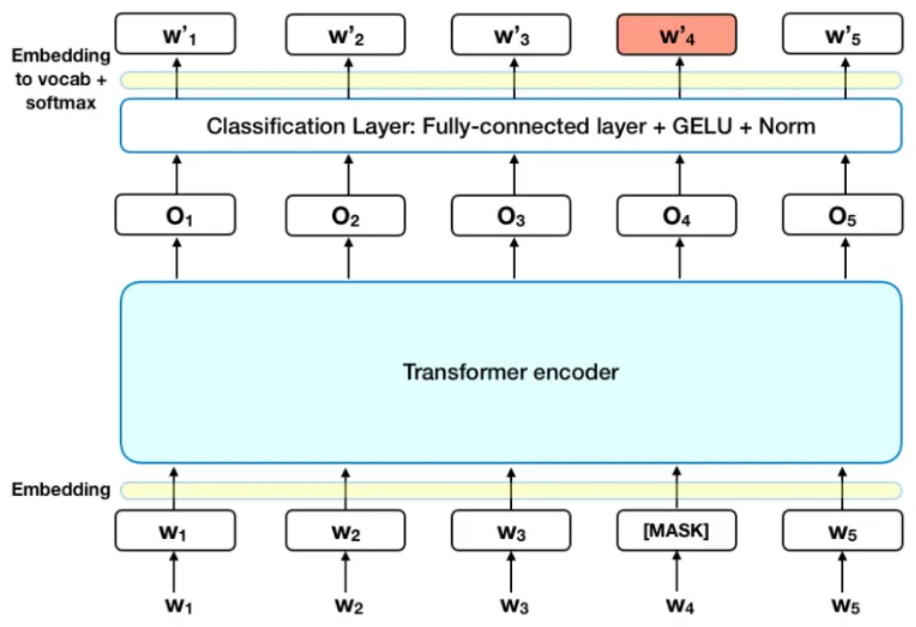
在将单词序列输入给 BERT 之前,每个序列中有 15% 的单词被 [MASK] token 替换。 然后模型尝试基于序列中其他未被 mask 的单词的上下文来预测被掩盖的原单词。
这样就需要:
- 在 encoder 的输出上添加一个分类层
- 用嵌入矩阵乘以输出向量,将其转换为词汇的维度
- 用 softmax 计算词汇表中每个单词的概率
BERT 的损失函数只考虑了 mask 的预测值,忽略了没有掩蔽的字的预测。这样的话,模型要比单向模型收敛得慢,不过结果的情境意识增加了,Transformer encoder不知道它将被要求预测哪些单词或哪些单词已被随机单词替换,因此它被迫保持每个输入token的分布式上下文表示。此外,因为随机替换只发生在所有token的1.5%(即15%的10%),这似乎不会损害模型的语言理解能力。
by Rani Horev
1.2 Next Sentence Prediction (NSP)
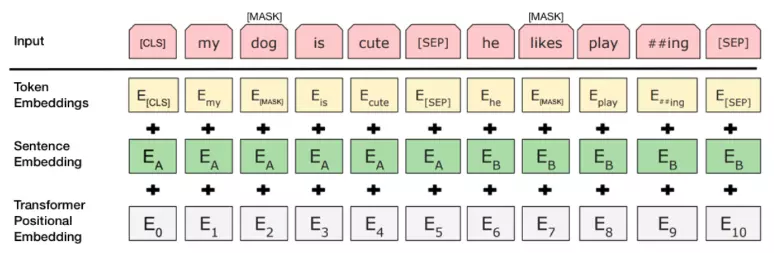
在 BERT 的训练过程中,模型接收成对的句子作为输入,并且预测其中第二个句子是否在原始文档中也是后续句子。在训练期间,50% 的输入对在原始文档中是前后关系,另外 50% 中是从语料库中随机组成的,并且是与第一句断开的。
为了帮助模型区分开训练中的两个句子,输入在进入模型之前要按以下方式进行处理:
- 在第一个句子的开头插入 [CLS] 标记,在每个句子的末尾插入 [SEP] 标记。
- 将表示句子 A 或句子 B 的一个句子 embedding 添加到每个 token 上。
- 给每个 token 添加一个位置 embedding,来表示它在序列中的位置。
为了预测第二个句子是否是第一个句子的后续句子,用下面几个步骤来预测:
- 整个输入序列输入给 Transformer 模型
- 用一个简单的分类层将 [CLS] 标记的输出变换为 2×1 形状的向量
- 用 softmax 计算 IsNextSequence 的概率
在训练 BERT 模型时,Masked LM 和 Next Sentence Prediction 是一起训练的,目标就是要最小化两种策略的组合损失函数。
1.3 fine-tunning
Fine-tuning方式是指在已经训练好的语言模型的基础上,加入少量的task-specific parameters, 例如对于分类问题在语言模型基础上加一层softmax网络,然后在新的语料上重新训练来进行fine-tune。例如OpenAI GPT 中采用了这样的方法,模型如下所示:
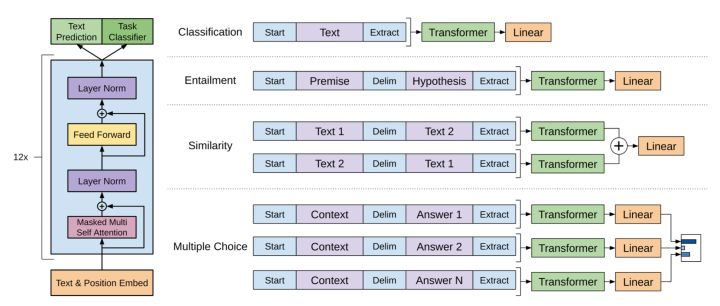 图 Transformer LM + fine-tuning模型示意图
图 Transformer LM + fine-tuning模型示意图
首先语言模型采用了Transformer Decoder的方法来进行训练,采用文本预测作为语言模型训练任务,训练完毕之后,加一层Linear Project来完成分类/相似度计算等NLP任务。因此总结来说,LM + Fine-Tuning的方法工作包括两步:
- 构造语言模型,采用大的语料A来训练语言模型
- 在语言模型基础上增加少量神经网络层来完成specific task例如序列标注、分类等,然后采用有标记的语料B来有监督地训练模型,这个过程中语言模型的参数并不固定,依然是trainable variables.而BERT论文采用了LM + fine-tuning的方法,同时也讨论了BERT + task-specific model的方法。
这里fine-tuning之前对模型的修改非常简单,例如对于sequence-level的分类任务,BERT直接取第一个[CLS]token的final hidden state C∈R^H ,加一层权重 W∈R^{K*H}后softmax预测label proba:
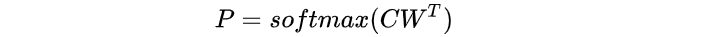
其他预测任务需要进行一些调整,如图:
可以调整的参数和取值范围有:
- Batch size: 16, 32
- Learning rate (Adam): 5e-5, 3e-5, 2e-5
- Number of epochs: 3, 4
因为大部分参数都和预训练时一样,精调会快一些,所以作者推荐多试一些参数。
2 实验结果
如前文所述,BERT在11项NLP任务中刷新了性能表现记录!在这一节中,团队直观呈现BERT在这些任务的实验结果,具体的实验设置和比较请阅读原论文.
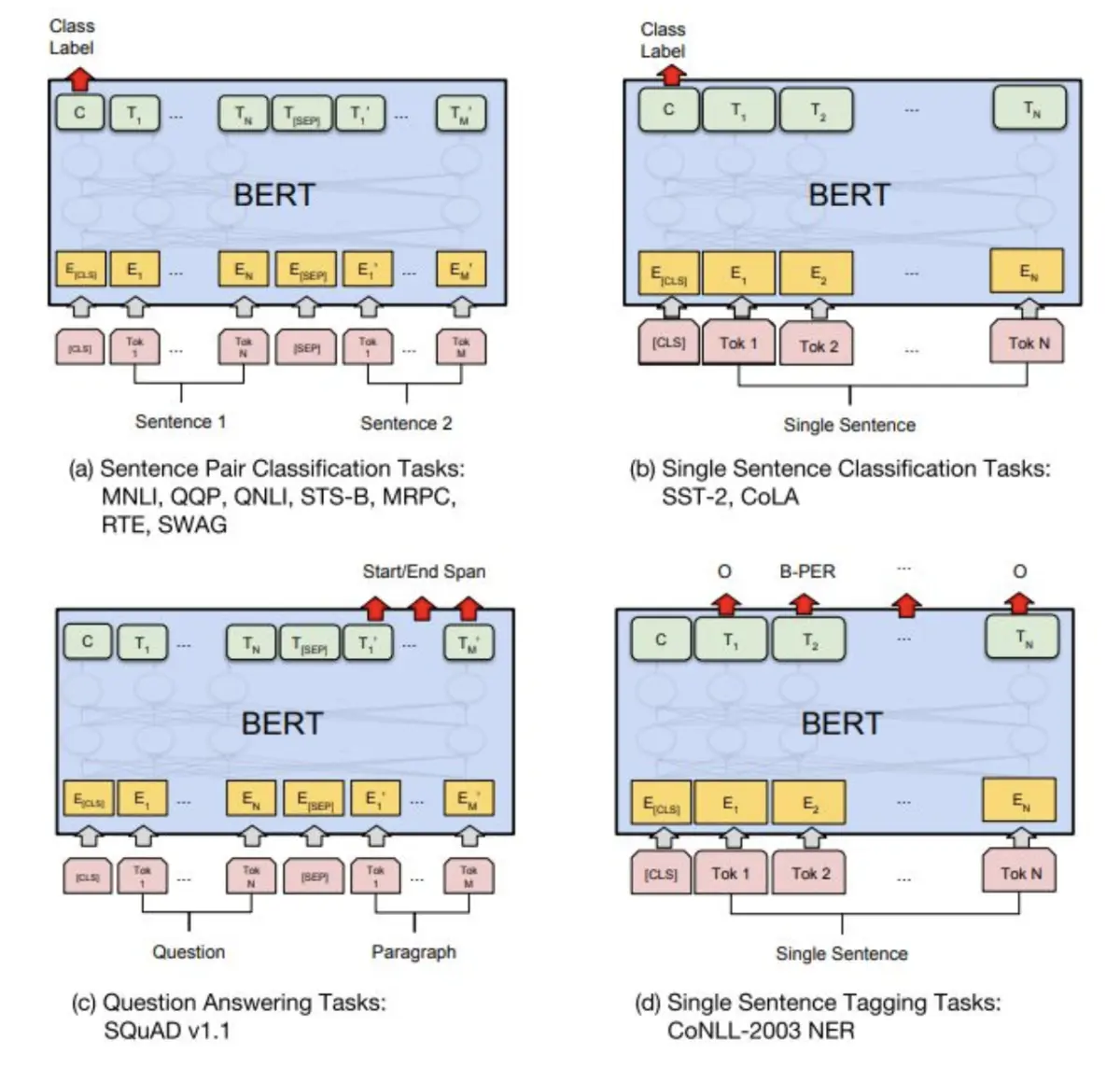
图3:我们的面向特定任务的模型是将BERT与一个额外的输出层结合而形成的,因此需要从头开始学习最小数量的参数。在这些任务中,(a)和(b)是序列级任务,而(c)和(d)是token级任务。在图中,E表示输入嵌入,Ti表示tokeni的上下文表示,[CLS]是用于分类输出的特殊符号,[SEP]是用于分隔非连续token序列的特殊符号。
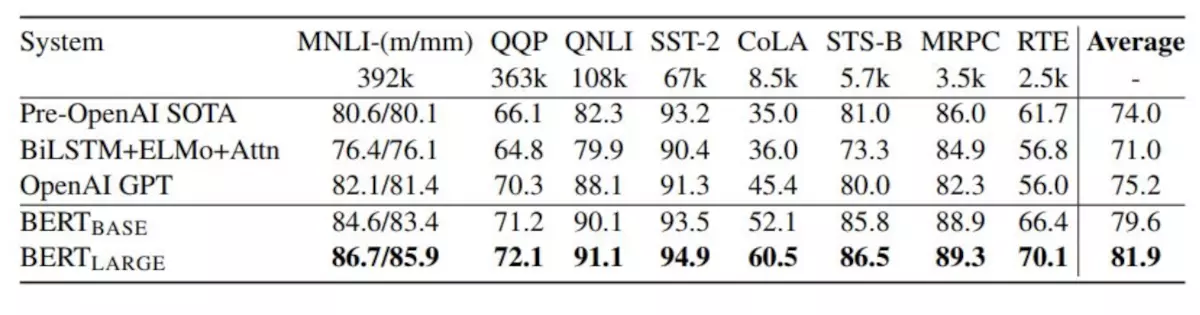
图4:GLUE测试结果,由GLUE评估服务器给出。每个任务下方的数字表示训练样例的数量。“平均”一栏中的数据与GLUE官方评分稍有不同,因为我们排除了有问题的WNLI集。BERT 和OpenAI GPT的结果是单模型、单任务下的数据。所有结果来自https://gluebenchmark.com/leaderboard和https://blog.openai.com/language-unsupervised/
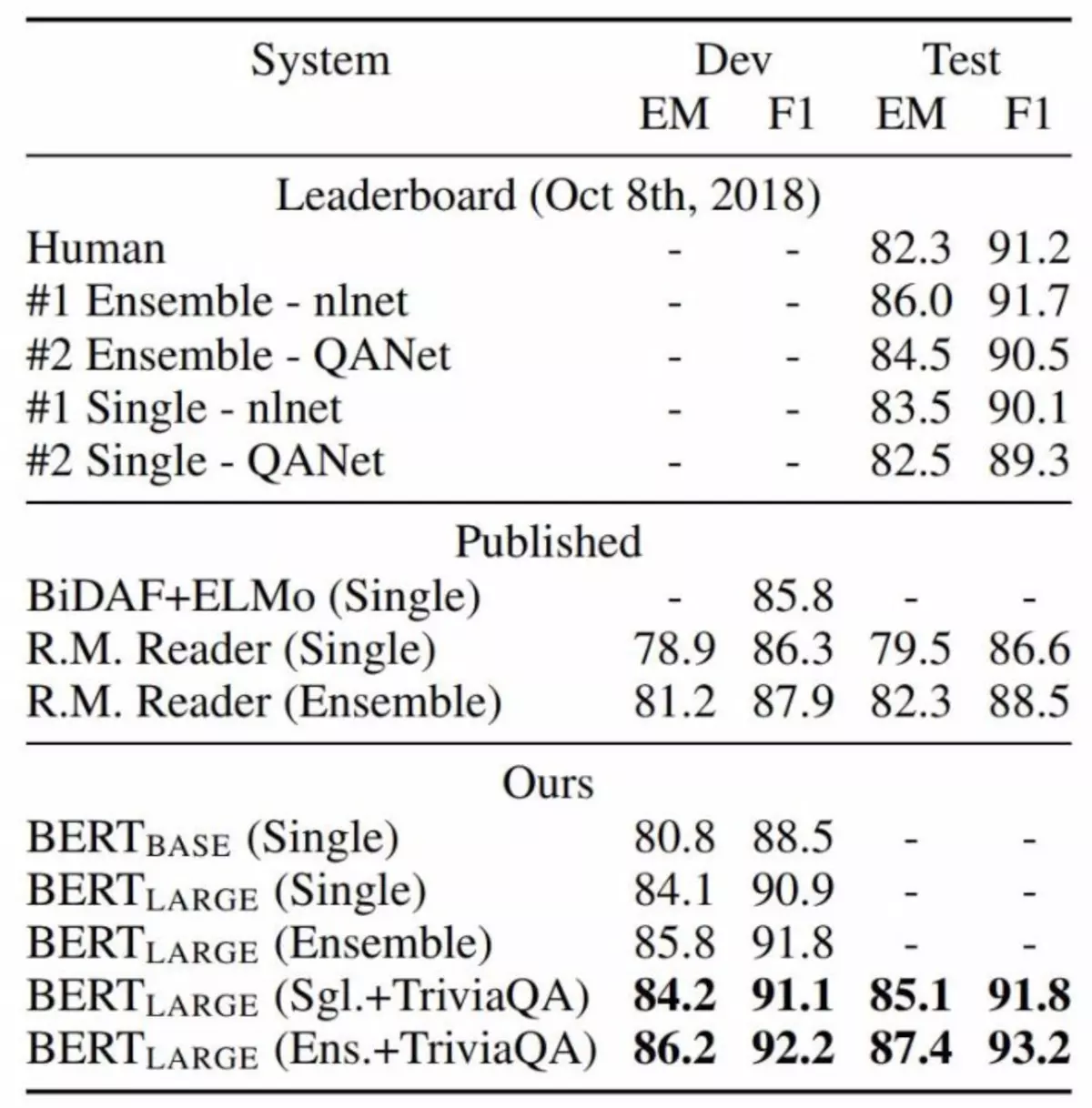
图5:SQuAD 结果。BERT 集成是使用不同预训练检查点和fine-tuning seed的 7x 系统。
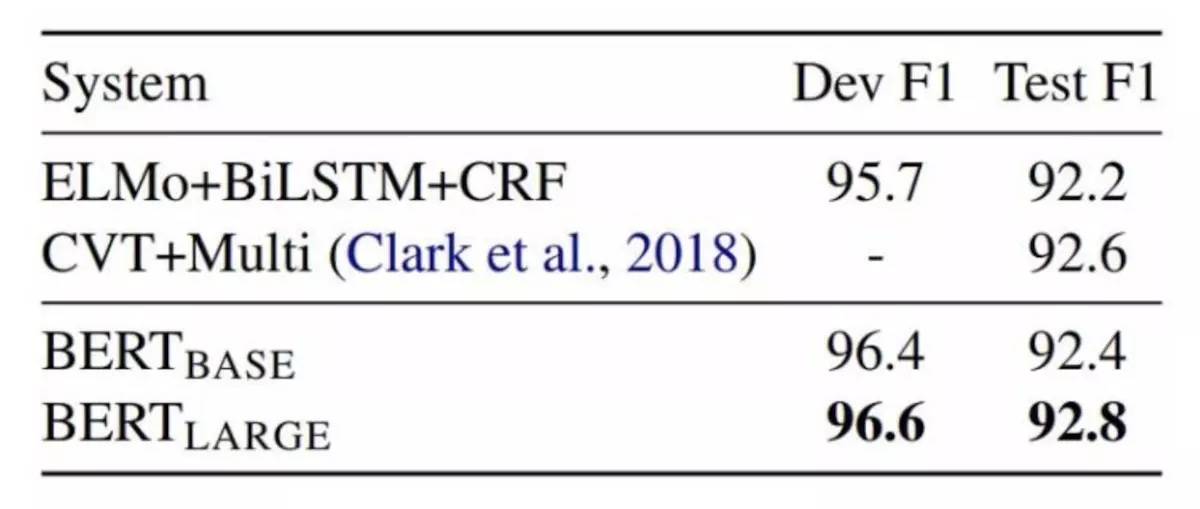
图6:CoNLL-2003 命名实体识别结果。超参数由开发集选择,得出的开发和测试分数是使用这些超参数进行五次随机重启的平均值。
3 总结
- BERT采用Masked LM + Next Sentence Prediction作为pre-training tasks, 完成了真正的Bidirectional LM
- BERT模型能够很容易地Fine-tune,并且效果很好,并且BERT as additional feature效果也很好
- 模型足够泛化,覆盖了足够多的NLP tasks
我们在momodel上fork了作者的代码以供大家学习参考.
另外,我们提供了一个文本情感分析的demo供大家参考https://momodel.cn/workspace/5ddcf5e0a822db646f75b1ab?type=app
4 参考资料
[1] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [2] https://www.jianshu.com/p/d110d0c13063 [3] https://zhuanlan.zhihu.com/p/50717786 [4] https://zhuanlan.zhihu.com/p/46997268 [5] https://zhuanlan.zhihu.com/p/46833276 [6] https://zhuanlan.zhihu.com/p/46652512 [7] https://www.jianshu.com/p/4dbdb5ab959b?from=singlemessage [8] https://www.cnblogs.com/rucwxb/p/10277217.html [9] https://juejin.im/post/5b339e2e518825749f256131#heading-0