转眼间我们的技术博客栏目也已经发布到第23期啦,小Mo已经为大家介绍了各种领域许多不同的机器学习算法与实现。之前呢,我们的工作人员也与Mo-AI俱乐部的大家做了小小的调研~希望能够做出更多大家想要看到的主题!
那第一个就是你啦,非常感谢这位朋友提给我们的意见,今天我们就来看看,在Mo平台上,怎么部署一个训练好的模型,能够方便大家直接调用。
1. 新建一个项目
在工作台中新建一个项目并进入开发页面,要部署的话,一定是选择新建项目。
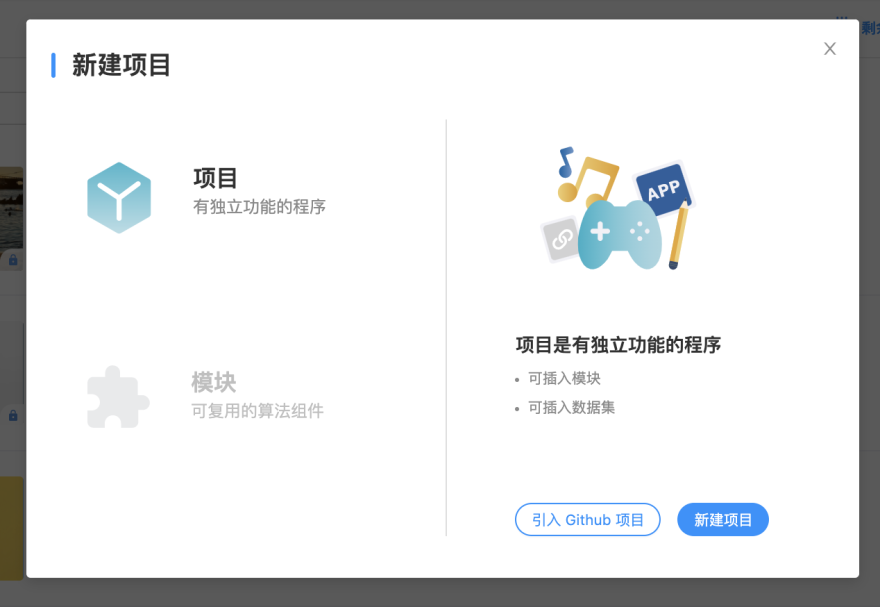
在当前新建的项目中,点击左侧 Files ,显示了当前工作目录下的文件和文件夹。
-
results文件夹,用于存放模型与checkpoints,其中的tb_results用于当使用TensorBoard功能时存放可视化数据。 _OVERVIEW.mdmarkdown文件,用于展示项目说明。_README.ipynb为介绍文档。- 打开
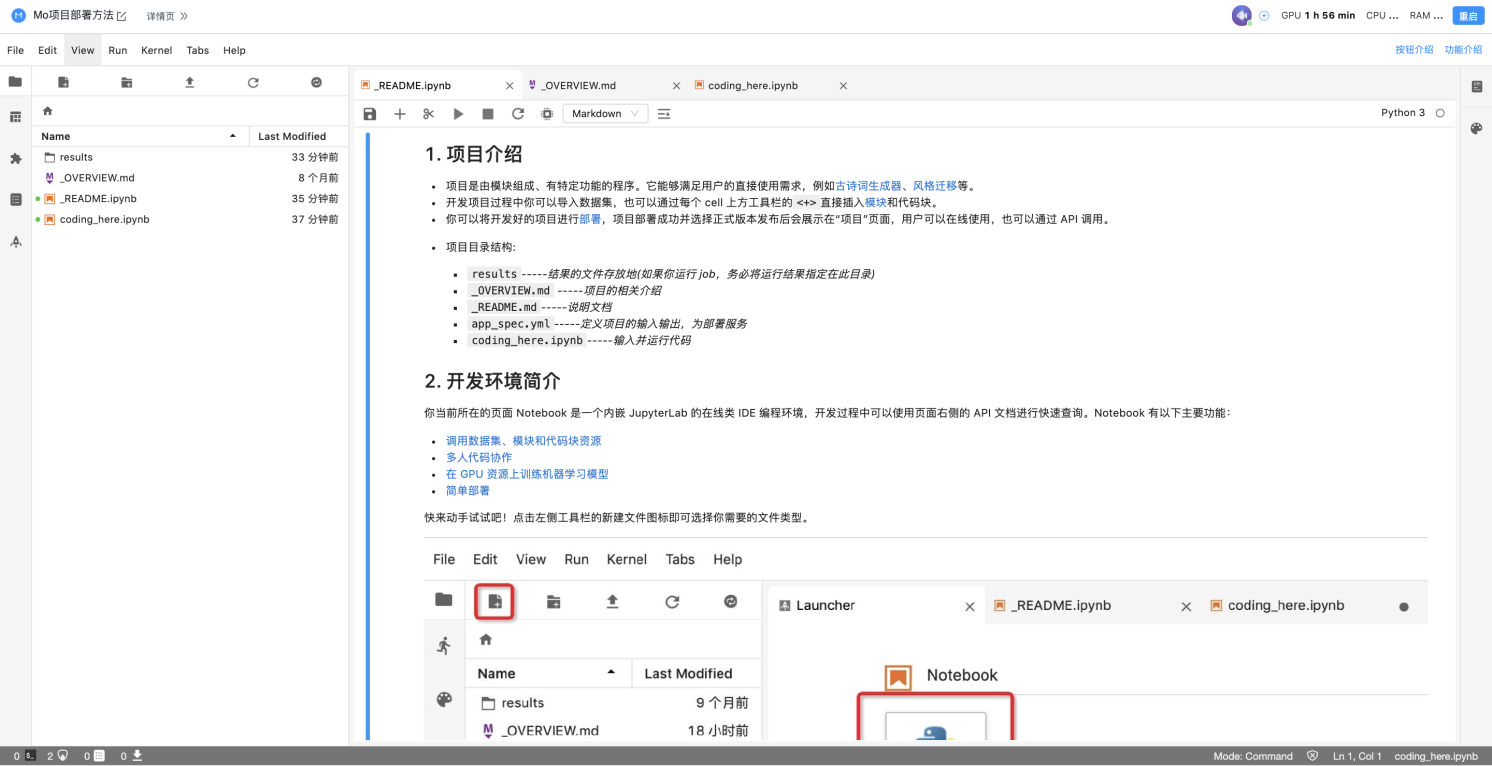
coding_here.ipynb或新建一个notebook(可参考帮助文档中的基本页面中的开发环境部分)。来开始我们的代码吧。
2. 编写模型的训练与预测代码
- 导入需要的python模块
import os import sys from sklearn.externals import joblib from sklearn.cluster import KMeans - 编写模型类
一般机器学习算法包括训练和预测两部分,经过训练过程会产生一个模型文件,在预测时调用训练好的模型文件进行预测。所以我们在程序中分为 train,predict 和 load_model 三种方法,kmeans 聚类算法主程序如下。
# 定义一个kmeans聚类模型,注意设置传参接口
class howtodeploymodulemodel(object):
# 模型初始化函数,本例中参数皆为传参
def __init__(self, conf={}):
'''
:param conf:
'''
pass
# 模型训练函数
def train(self, conf={}):
'''
:param conf:
:return:
'''
# 获取传入参数 n_clusters聚类数 random_state随机状态
n_clusters = conf['n_clusters'] # value_type: int # description: number of clusters
random_state = conf['random_state'] # value_type: int # description: RandomState instance or None
if 'file_path' in conf:
file_path = conf['file_path'] # value_type: str # description: file path of data file
data = np.loadtxt(file_path, dtype=np.str, delimiter=",").astype(np.float)
if 'data' in conf:
data = conf['data'] # value_type: np.array # description: data for train
# 定义模型
kmeans = KMeans(n_clusters=n_clusters, random_state=random_state).fit(data)
# 保持模型
if 'save_path' in conf:
save_path = conf['save_path'] # value_type: str # description: save path of trained model
s = joblib.dump(kmeans, save_path)
else:
s = joblib.dump(kmeans, self.checkpoint_dir+'/howtodeploymodulemodel.pkl')
return '训练完成'
# 模型预测函数
def predict(self, conf={}):
'''
:param conf:
:return:
'''
data = conf['data'] # value_type: np.array # description: data for predict
if 'save_path' in conf:
save_path = conf['save_path'] # value_type: str # description: save path of trained model
kmeans = self.load_model(save_path)
else:
kmeans = self.load_model()
return kmeans.predict(data)
# 载入模型
def load_model(self, file="./results"+"/howtodeploymodulemodel.pkl"):
'''
:param conf:
:return:
'''
kmeans = joblib.load(file)
return kmeans
print('kmeans聚类算法类定义完成')
kmeans聚类算法类定义完成
- 训练过程
设定训练模型的保存路径,训练数据等参数,训练产生算法模型文件。
conf = {"save_path": './results/xx.pkl', "data":[[1,1,1],[2,2,2]],"n_clusters":2,"random_state":0}
print(conf)
module = howtodeploymodulemodel(conf)
result = module.train(conf)
result
‘训练完成’
- 预测过程 ```python conf = {“data”:[[1,1,1]], “save_path”: ‘./results/xx.pkl’} print(conf)
module = howtodeploymodulemodel(conf) result = module.predict(conf) result
现在,我们的模型就已经测试完成啦!
当然, 我们这里只是一个示例,模型没有很大, 训练的 epoch 也很小,效果提升不明显. 如果你使用的模型模块是基于深度神经网络的,并且网络结构很大,那么训练时间会比较长,这时候可以创建 job 并使用 GPU 来加速训练过程,详见[这里](https://momodel.cn/docs/#/zh-cn/%E5%9C%A8GPU%E6%88%96CPU%E8%B5%84%E6%BA%90%E4%B8%8A%E8%AE%AD%E7%BB%83%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E6%A8%A1%E5%9E%8B)
## 3. 部署应用
现在就要开始最重要的步骤了!也就是部署步骤!在本例中,我们希望其他人在调用我们的服务后能够直接使用我们训练好的模型进行预测,输入时待遇测的值,输出是聚类结果。
我们的功能代码在 Notebook 调试完成后就可以点击左侧的部署图标,按照指引部署应用。
### 1. 开始部署
在 Notebook 中点击左侧栏中的部署图标,进入部署页面。
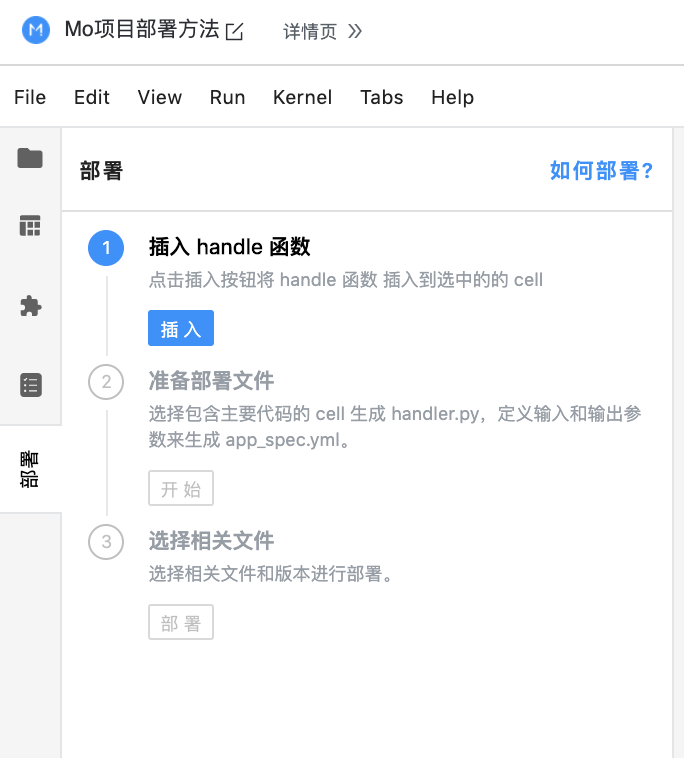
### 2. 插入handle函数
handle函数是应用函数的的主函数,也是把输入和输出参数对应起来的接口函数,是部署之后其他人调用你的服务的处理方法。选中 Cell 代码的地方,点击第一步的“插入”按钮插入handle函数。
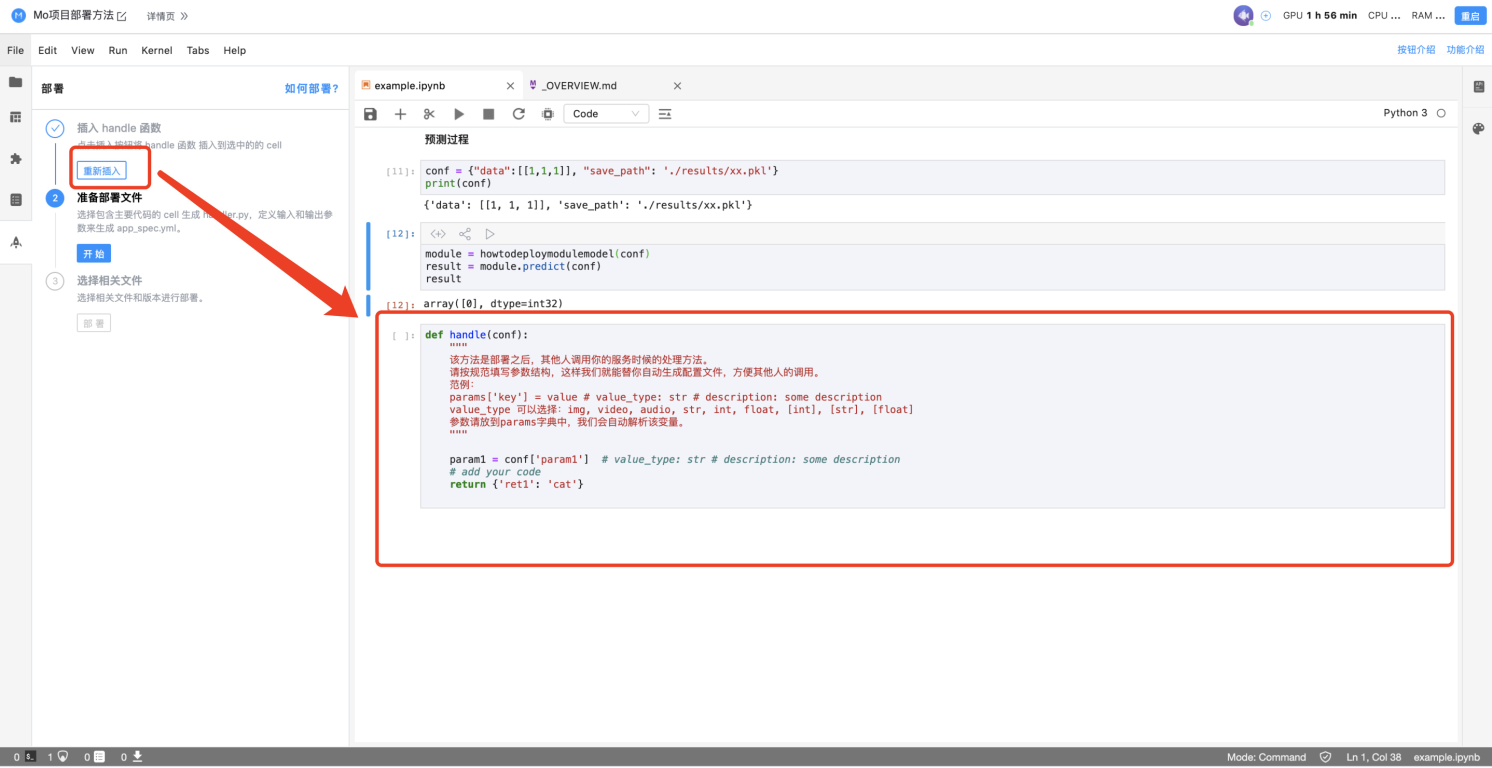
可以看到,在我们的notebook结尾处,新增了一个handle函数。这就是部署最重要的步骤啦!
`handle` 方法,就是部署完成后,其他人调用我们整个项目时会的处理方法。比如说,在本例中,如果希望其他人在调用我们的服务后能够直接使用我们训练好的模型进行预测的话,在handle函数中就应该调用模型的预测函数 `module.predict` ,返回则应该是 `result` , 如下所示:
```python
def handle(conf):
module = howtodeploymodulemodel(conf)
result = module.predict(conf)
return {'ret1': result}
在现在版本中,我们的输入输出参数可以选择以下变量,本例中,参数都放在 conf 字典中。
value_type :img, video, audio, str, int, float, [int], [str], [float]
大家写好了 handle 函数,同样也要在notebook中测试一下哦!
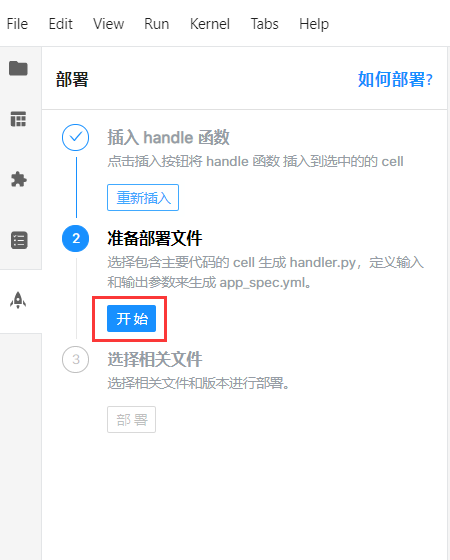
3. 准备部署文件
整理好 handle 函数之后,点击第二步的”开始”按钮,开始准备部署时需要的文件。
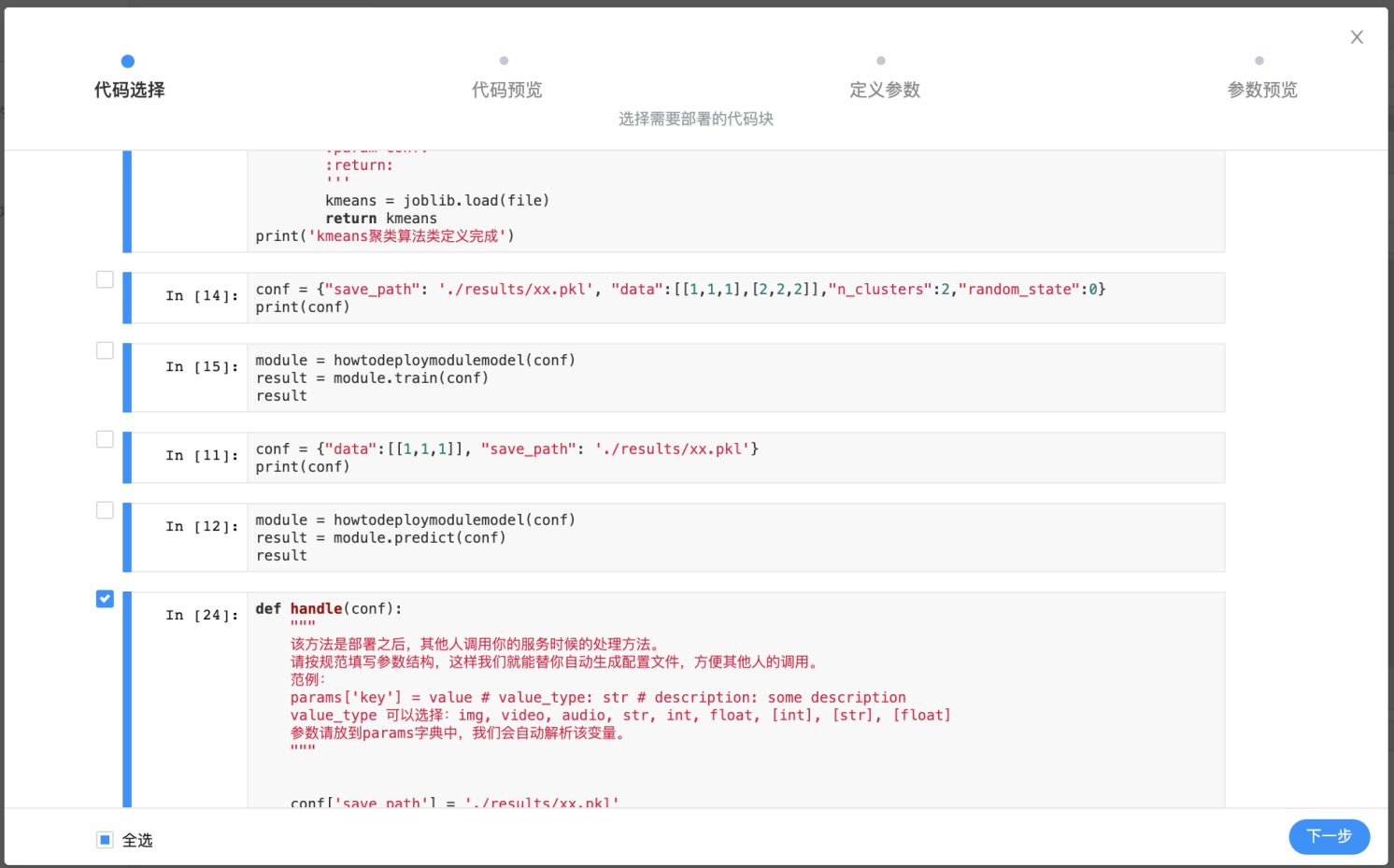
然后我们会进入准备文件的第一步,代码选择。在这一步中,我们一定要注意,训练用代码和测试用代码不用勾选进去哦。
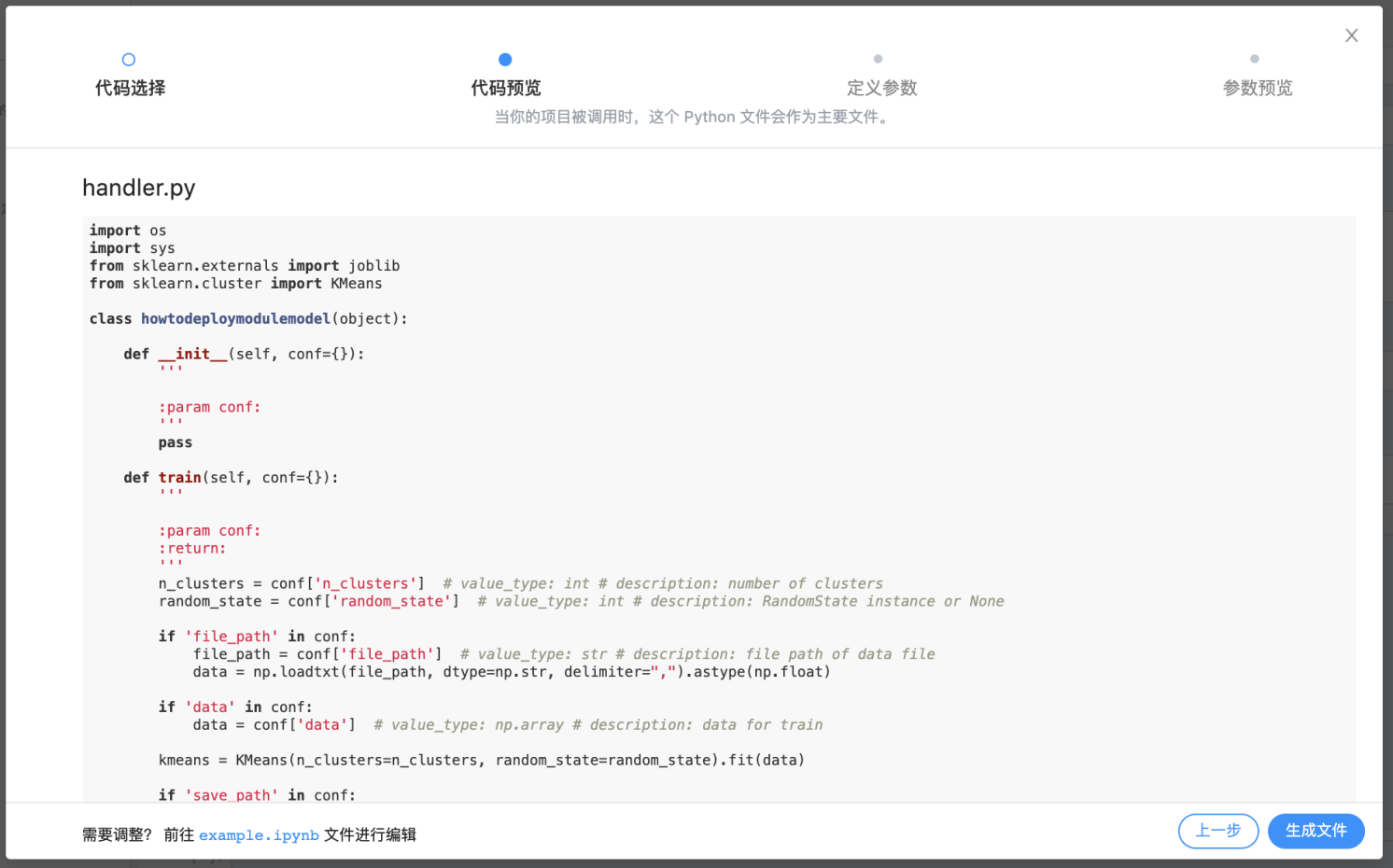
 第二步,代码预览步骤,系统会将我们勾选的notebook cell 转化成python文件,如果有不需要的部分可以回到原文件进行修改。
第二步,代码预览步骤,系统会将我们勾选的notebook cell 转化成python文件,如果有不需要的部分可以回到原文件进行修改。
第三步定义参数,这一步就会定义我们的输入和输出。对应我们的例子,我们会:
- 输入一个参数
data,它是一个int数组,代表着输入一个点的三维坐标。 - 输出一个
ret1,它是一个int型整数,代表我们输入的所属类别。

最后,在参数预览步骤,我们可以查看我们的参数定义,同时也可以查看我们最后服务接口的预览:

4. 部署应用项目
完成所有以上步骤后,点击第3步的 部署 按钮进行项目部署。
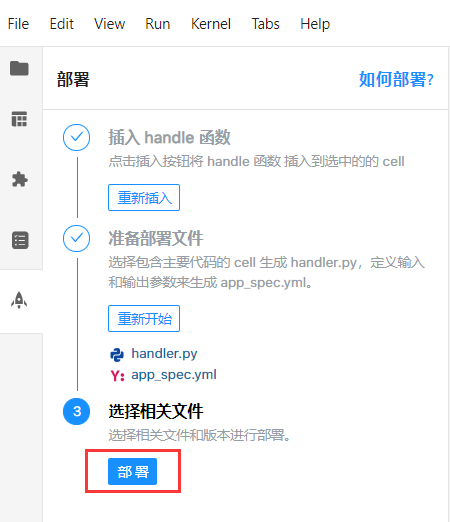
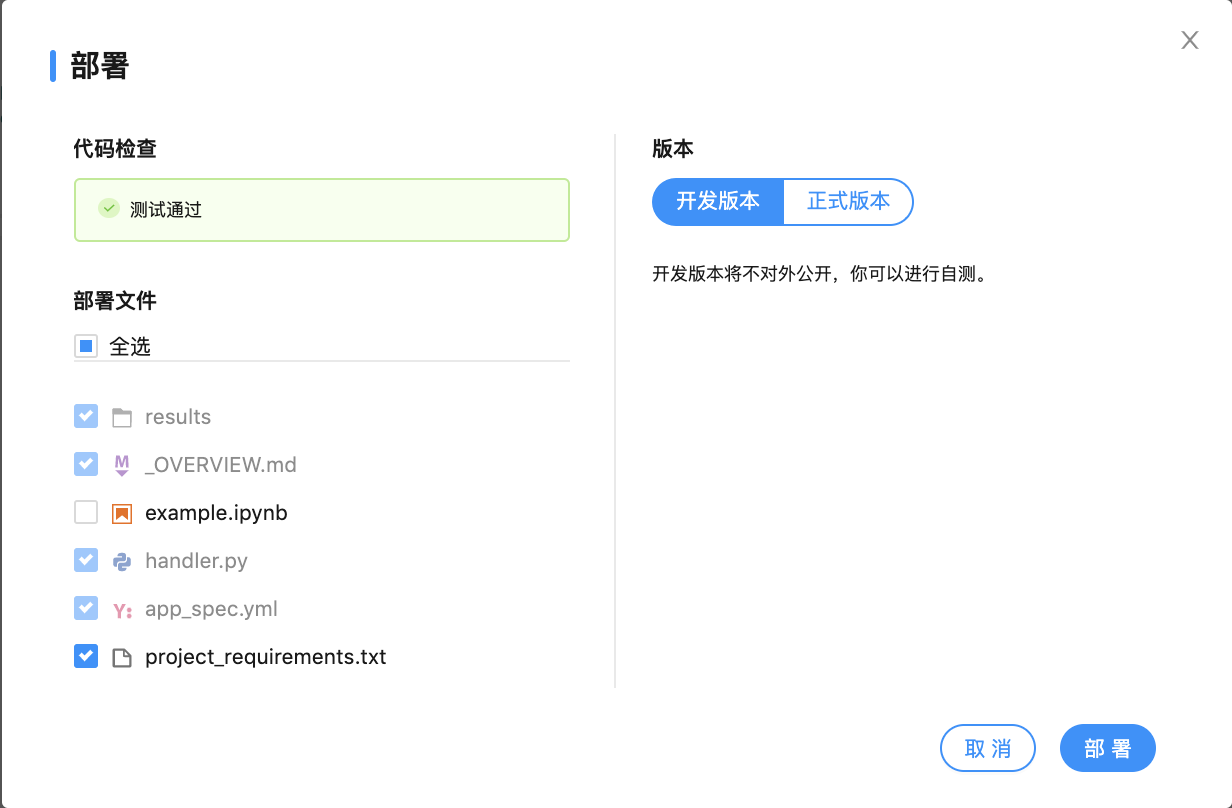
在部署的时候,系统会自动生成 handler.py 文件和 app_spec.yml 配置文件,你可以选择需要发布的文件或勾选发布开发版本或正式版本(开发版本部署后只有所有者可以使用,正式版项目为公开的,所有人可见),然后点击“完成”,进行部署。
在这里,我们先选择发布 dev 开发版本,进行自测调整。
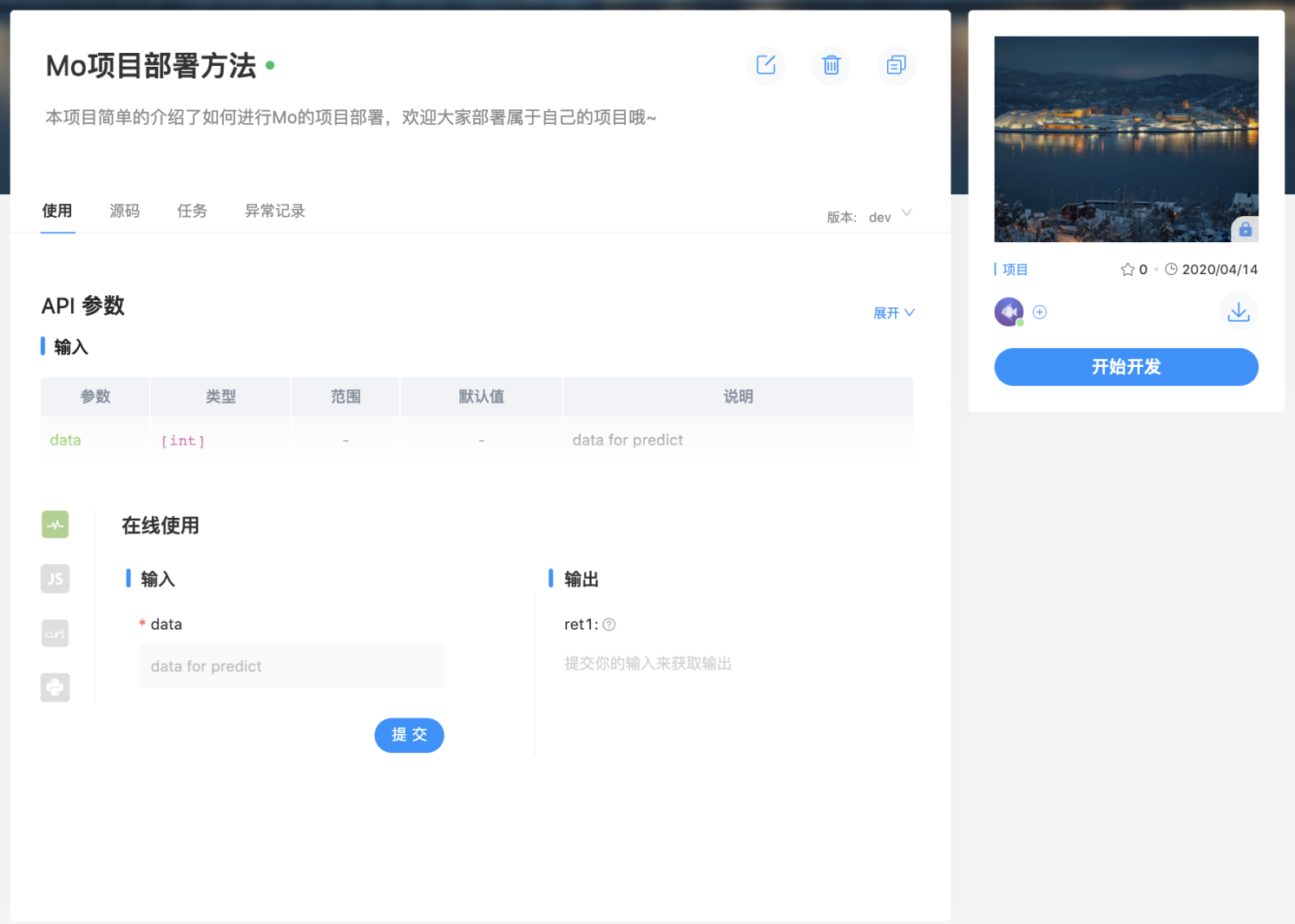
在短暂的等待后, 回到应用的详情页面, 在右上角会有部署成功的通知。恭喜你!你已经完成了你的第一个APP的部署。回到详情页,我们也可以看懂现在已经有使用界面啦!
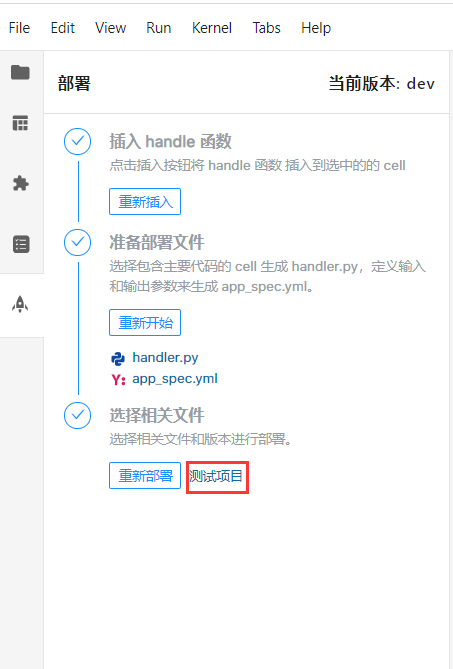
4. 完成测试
我们可以选择在部署栏里点击测试项目,在网页中输入参数,运行得到输出结果,如果发现问题,可再回到项目中进行调试。
测试完成没有问题的话,我们就可以重新部署一个公开版本啦~
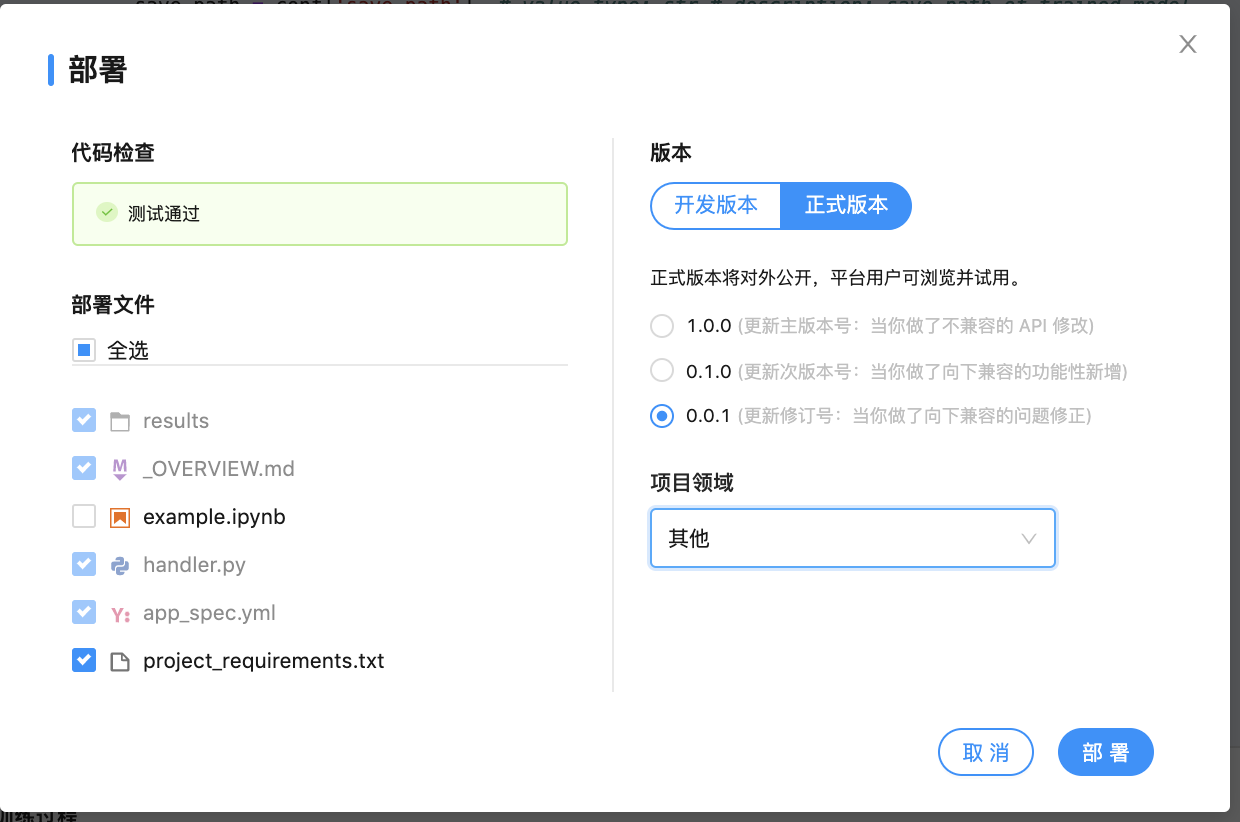
这样就公开项目并且做出自己的说明哦。
大家来自己尝试着部署自己的机器学习模型吧!
项目地址:https://momodel.cn/explore/5e9577f194a447b8519ae492?type=app
##关于我们 Mo(网址:https://momodel.cn) 是一个支持 Python的人工智能在线建模平台,能帮助你快速开发、训练并部署模型。
近期 Mo 也在持续进行机器学习相关的入门课程和论文分享活动,欢迎大家关注我们的公众号获取最新资讯!
