What is dataset
Datasets are essential for machine learning and they are the source of knowledge. Usually datasets are collected for specific tasks, such as historical weather data for a region, traffic data for a city, historical transaction data for a stock market, capacity data for a factory, and so on. Your every movement, such as your consumption record, also produces data. Data is common, but it often needs to be collected with care.
Explore dataset
From daily weather data to brain nerve data, our website includes many different types of datasets. Some of these datasets are publicly released from research institutions or government agencies, and many are shared by enthusiasts like you. You can find them on the explore page and then browse through the details page. Come and search for interesting datasets. If you find it interesting or helpful, don’t forget to give it a star.
Upload your dataset
Of course, if you have some interesting or fun datasets yourself, you are welcome to share them. Maybe your data can help others and make the world a better place. Sharing data is very simple: just create a new dataset project, upload your data.

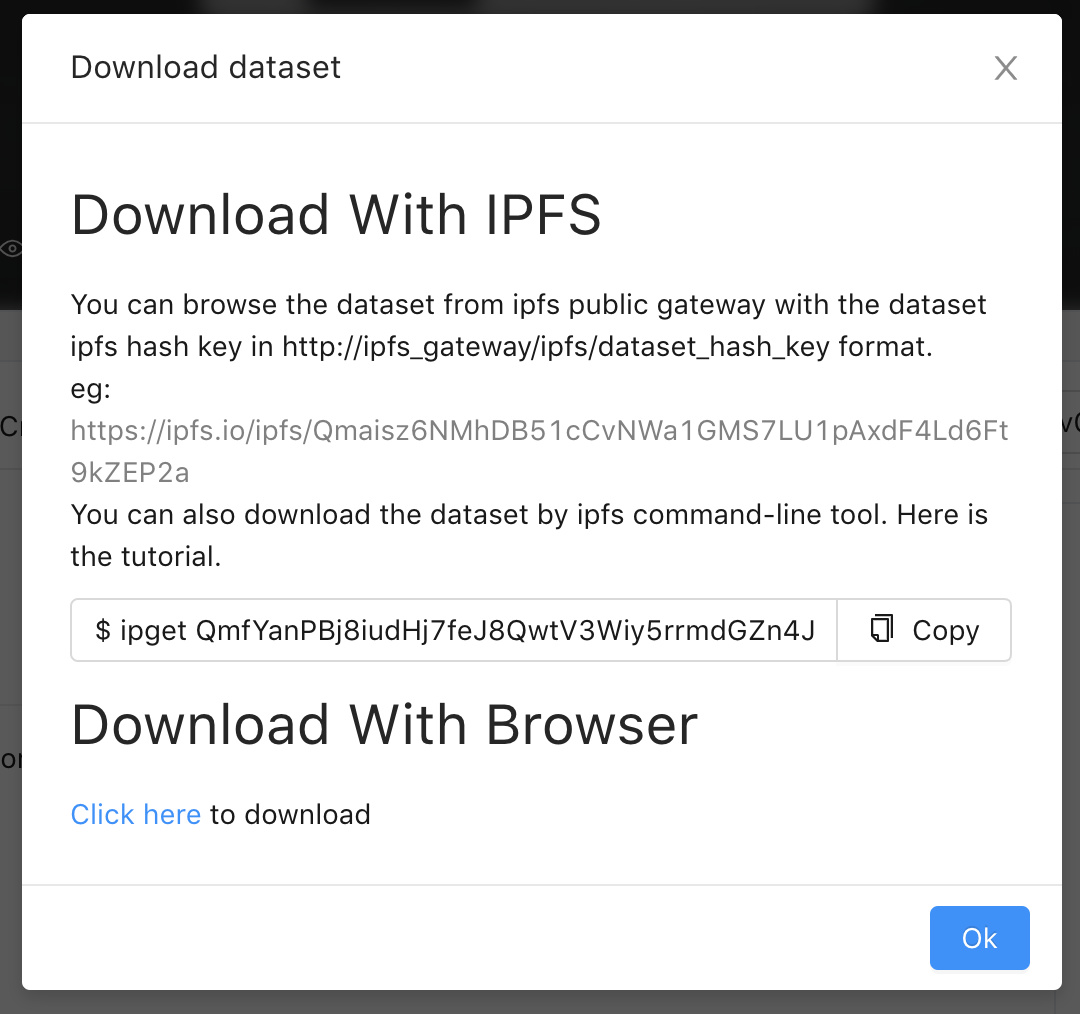
Then you can preview your data in the preview tab. If you want to share your data with others, you can make a release.We will upload your data to the IPFS system after you confirming the release. In this way, Mo users around the world can see your data. Share your data and let us build a data library together.
Work on your dataset
Maybe you are a newbie, you simply want to discover the beauty of data; or you are already an expert, you want to explore the value of data. No matter who you are, you can easily process data, analyze data, and model on our website. Create a module project, introduce your favorite dataset, and start your exploration.
Dataset crowdsourcing
For supervised machine learning, labeled data is required. However, a large amount of data is unlabeled. We provide a full-featured data crowdsourcing function, which can automatically distribute data to others for labeling. When the data has been labeled, we will automatically train your model. Now, create a project and have a try. You can see more details on your Docs .