- .ipynb_checkpoints
- data
- datasets
- job_logs
- results
- .gitignore
- _overview.md
- app_spec.yml
- char_rnn_model.py
- config_poem.py
- data_loader.py
- file.zip
- handler.py
- intro.ipynb
- main.ipynb
- project_requirements.txt
- rhyme_helper.py
- test.ipynb
- train.py
- Untitled.ipynb
- untitled.md
- Untitled1.ipynb
- word2vec_helper.py
- work.zip
- write_poem.py
intro.ipynb @81e1308 — view markup · raw · history · blame
第一回合:春
《春晓》孟浩然
《春眠啼鸟》Mo
第二回合:夏
《晓出净慈寺送林子方》杨万里
《映日荷花》Mo
第三回合:秋
《山居秋暝》王维
《空山新雨》Mo
第四回合:冬
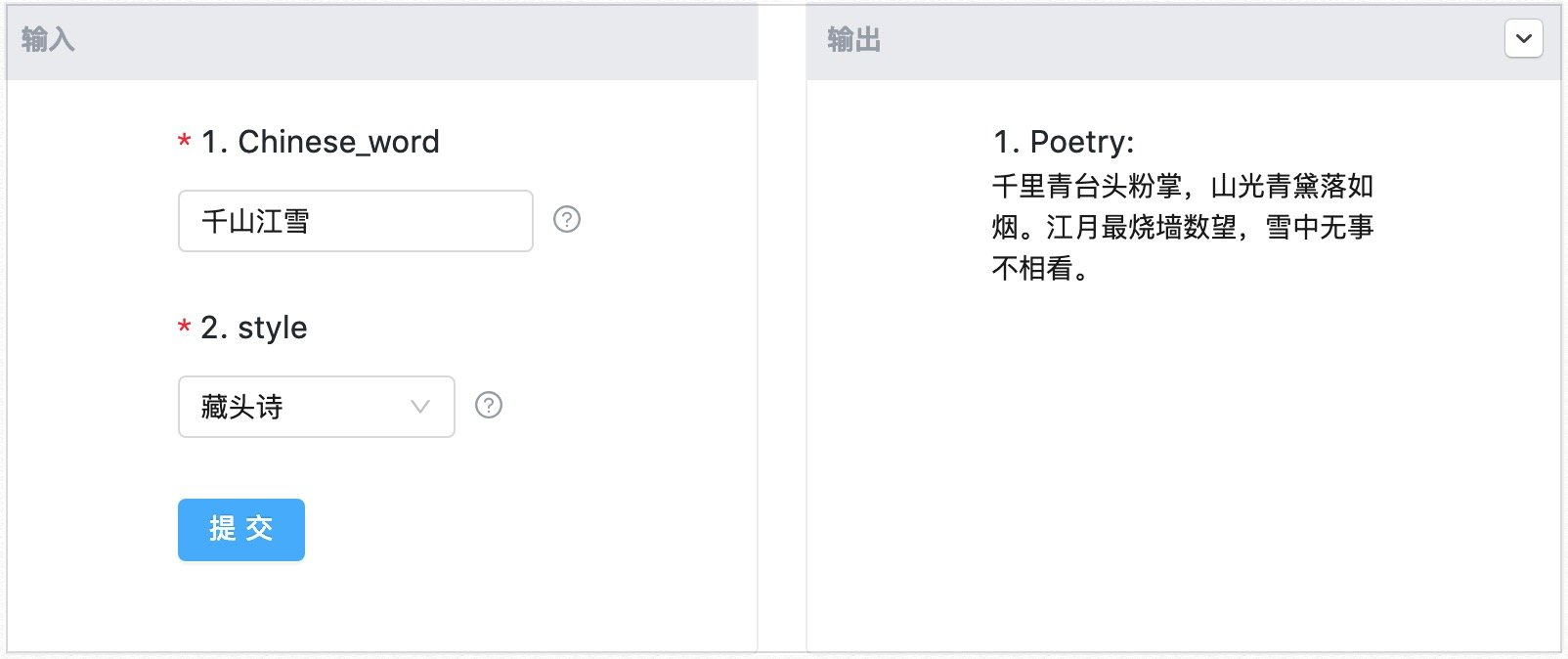
《江雪》柳宗元
《千山江雪》Mo
怎么样,AI 没有让你失望吧?Mo 写出的诗句不仅和四季相关,还从“对手”的诗句中提取了关键词进行藏头,这波666的操作想不佩服都不难!下面让我们一起来了解 AI 写诗背后的奥秘——深度学习算法。
深度学习
深度学习是一类机器学习方法,可实例化为深度学习器,所对应的设计、训练和使用方法集合称为深度学习。深度学习器由若干处理层组成,每层包含至少一个处理单元,每层输出为数据的一种表征,且表征层次随处理层次增加而提高。
深度的定义是相对的。针对某具体场景和学习任务,若学习器的处理单元总数和层数分别为 M 和 N ,学习器所保留的信息量或任务性能超过任意层数小于 N 且单元总数为 M 的学习器,则该学习器为严格的或狭义的深度学习器,其对应的设计、训练和使用方法集合为严格的或狭义的深度学习。
深度学习听起来高深,落地的应用却可以很浪漫。比如作诗、作曲、人脸美容美妆等都可以实现。下面我们以古诗词生成器为例,一步一步带你从数据处理到模型搭建,再到训练出古诗词生成模型。
LSTM 介绍
像诗词文本这样的数据,文字的前后文存在关联性被称为序列化数据,即前一数据和后一个数据有顺序关系。深度学习中有一个重要的分支是专门用来处理这样的数据的——循环神经网络。循环神经网络广泛应用在自然语言处理领域( NLP ),今天我们带你介绍循环神经网络一个重要的改进算法模型 - LSTM。这里不对 LSTM 的原理进行深入,想要深入理解 LSTM 的可以戳这里《[译] 理解 LSTM 网络》。
数据处理
我们使用76748首古诗词作为数据集,数据集下载链接,原始的古诗词的存储形式如下:

我们可以看到原始的古诗词是文本符号的形式,无法直接进行机器学习,所以我们第一步需要把文本信息转换为数据形式,这种转换方式就叫词嵌入(word embedding),我们采用一种常用的词嵌套(word embedding)算法 - Word2vec 对古诗词进行编码。关于 Word2Vec 这里不详细讲解,有兴趣的可以参考《[NLP] 秒懂词向量Word2vec的本质》。在词嵌套过程中,为了避免最终的分类数过于庞大,可以选择去掉出现频率较小的字,比如可以去掉只出现过一次的字。Word2vec 算法经过训练后会产生一个模型文件,我们就可以利用这个模型文件对古诗词文本进行词嵌套编码。
经过第一步的处理已经把古诗词词语转换为可以机器学习建模的数字形式,因为我们采用 LSTM 算法进行古诗词生成,所以还需要构建输入到输出的映射处理。例如:“[长河落日圆]”作为 train_data,而相应的 train_label 就是“长河落日圆]]”,也就是“[”->“长”,“长”->“河”,“河”->“落”,“落”->“日”,“日”->“圆”,“圆”->“]”,“]”->“]”,这样子先后顺序一一对相。这也是循环神经网络的一个重要的特征。这里的“[”和“]”是开始符和结束符,用于生成古诗的开始与结束标记。
总结一下数据处理的步骤:
- 读取原始的古诗词文本,统计出所有不同的字,使用 Word2Vec 算法进行对应编码;
- 对于每首诗,将每个字、标点都转换为字典中对应的编号,构成神经网络的输入数据 train_data;
- 将输入数据左移动构成输出标签 train_label;
经过数据处理后我们得到以下数据文件:
- poems_edge_split.txt:原始古诗词文件,按行排列,每行为一首诗词;
- vectors_poem.bin:利用 Word2Vec 训练好的词向量模型,以</s>开头,按词频排列,去除低频词;
- poem_ids.txt:按输入输出关系映射处理之后的语料库文件;
- rhyme_words.txt: 押韵词存储,用于押韵诗的生成;
模型构建及训练
这里我们使用2层的 LSTM 框架,每层有128个隐藏层节点,我们使用 tensorflow.nn 模块库来定义网络结构层,其中 RNNcell 是 tensorflow 中实现 RNN 的基本单元,是一个抽象类,在实际应用中多用 RNNcell 的实现子类 BasicRNNCell 或者 BasicLSTMCell ,BasicGRUCell;如果需要构建多层的 RNN,在 TensorFlow 中,可以使用 tf.nn.rnn_cell.MultiRNNCell 函数对 RNNCell 进行堆叠。模型网络的第一层要对输入数据进行 embedding,可以理解为数据的维度变换,经过两层 LSTM 后,接着 softMax 得到一个在全字典上的输出概率。模型网络结构如下:

训练时可以定义 batch_size 的值,是否进行 dropout,为了结果的多样性,训练时在 softmax 输出层每次可以选择 topK 概率的字符作为输出。训练完成后可以使用 tensorboard 对网络结构和训练过程可视化展示。这里推荐用咱们自家建模平台 Mo,带有完整的 Python 和机器学习框架运行环境,并且有免费的 GPU 可以使用,大家可以自己试试哦。
诗词生成
调用前面训练好的模型我们就可以实现一个古诗词的应用了,刚刚 Mo 写的诗就是这样生成的: